Methods
Metrics
The FAIR principles represent “domain-independent, high-level principles that can be applied to a wide range of scholarly outputs” (Wilkinson et al. 2016). Therefore, we have considered the broadest possible and most interdisciplinary range of applications and proposed domain agnostic metrics to evaluate research data FAIRness instead of community specifics. The FAIRsFAIR Data Object Assessment Metrics are based on the indicators proposed by the RDA FAIR Data Maturity Model Working Group (FAIR Data Maturity Model Working Group 2020), the WDS/RDA Assessment of Data Fitness for Use checklist (Austin et al. 2019) as well as on results of the FAIRdat[4] and FAIREnough[5] projects. We have improved the metrics at several stages, considering the feedback from FAIR stakeholders through, e.g., a focus group study, open consultation and pilot repositories.
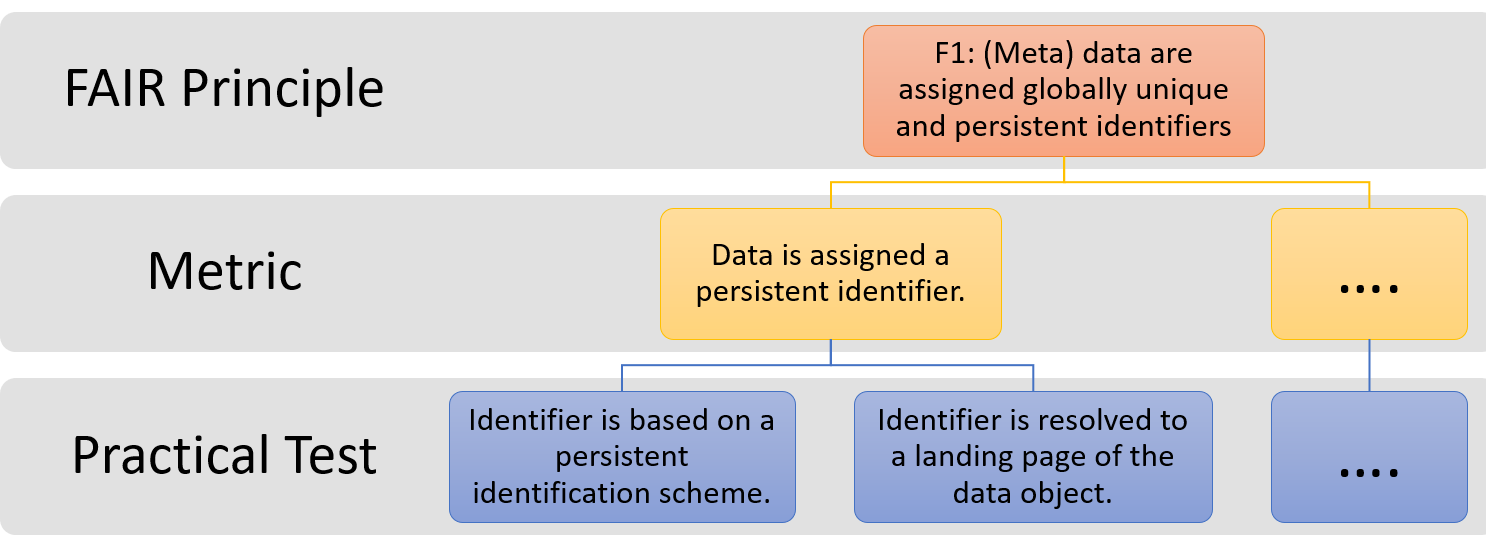
Figure 2. An example of the hierarchical relationship between principle, metric and practical tests.
The metrics defined are core metrics focussing on generally applicable data and metadata characteristics.
As FAIR principles are quite abstract and rather generically defined from a higher perspective we specified one or more metrics for each FAIR principle. Since each metric can be tested in various means depending on data contexts and current best practises we additionally proposed one or more practical tests to evaluate datasets against a particular metric. This results in a hierarchical model for our metrics in which each FAIR principle is assigned several metrics, which in turn can be assigned several tests. For example, metric ‘FsF-F1-02D’ (Data is assigned a persistent identifier) can be evaluated by two practical tests (Fig. 2). The first test verifies if a given identifier is based on a known persistent identifier scheme or syntax and the second test checks if the identifier resolves to a digital resource (i.e., landing page) of the object. Such a hierarchical model is beneficial since it allows to aggregate scores resulting from the tests to communicate the FAIRness of a dataset as a whole, by principle or by metric individually.
Each metric is uniquely identified according to the following syntax (in EBNF notation):
FsFMetricLabel ::= "FSF-"([FAIR][0-9]("."[0-9])?)("-"[0-9]+) ('M'|'D'|'MD') |
For example, the identifier of the metric ‘FsF-F1-02D’ starts with a project abbreviation for FAIRsFAIR (FsF), followed by the related FAIR principle identifier (F2) and a local identifier (01). The last part of the identifier refers to the resource that will be evaluated based on the metric, e.g., data (D), metadata (M) or both (MD).
Seventeen metrics have been defined and improved during an iterative process which involved several stakeholders such as a number of data publishers, international initiatives such as OGC, RDA and WDS as well as the EOSC FAIR working group. The latest version of the FAIRsFAIR metrics has been announced at the project’s website (https://www.fairsfair.eu/fairsfair-data-object-assessment-metrics-request-comments) available for public comments. In addition, each publication-ready version of the metrics have been uploaded and published at Zenodo (https://doi.org/10.5281/zenodo.4081213) providing a long-term record of all versions and allowing others to cite them when re-using the metrics in other contexts. The table (Tab. 1) below shows the latest version of the metrics as well as prose descriptions of associated tests.
Ongoing iterative development of F-UJI has allowed us to specify these tests in more detail, a new version of the metrics which is included as appendix in this report and will be published at Zenodo following public consultation. This version also includes specifications and justifications for the scoring schemes used for each test to qualitatively and quantitatively assess each investigated data object.
Principle | Metrics | Practical Tests |
F1 | FsF-F1-01D Data is assigned a globally unique identifier |
|
F1 | FsF-F1-02D Data is assigned a persistent identifier |
|
F2 | FsF-F2-01M Metadata includes descriptive core elements to support data findability. |
|
F3 | FsF-F3-01M Metadata includes the identifier of the data it describes. |
|
F4 | FsF-F4-01M Metadata is offered in such a way that it can be retrieved by machines. |
|
A1 | FsF-A1-01M Metadata contains access level and access conditions of the data. |
http://vocabularies.coar-repositories.org/documentation/access_rights/ http://purl.org/eprint/accessRights http://publications.europa.eu/resource/authority/access-right |
A1 | FsF-A1-02M Metadata is accessible through a standardized communication protocol |
|
A1 | FsF-A1-03D Data is accessible through a standardized communication protocol |
|
A2 | FsF-A2-01M Metadata remains available, even if the data is no longer available. | Programmatic assessment of the preservation of metadata of a data object can only be tested if the object is deleted or replaced. So this test is only applicable for deleted, replaced or obsolete objects. Importantly, continued access to metadata depends on a data repository’s preservation practice. Therefore, we regard that the assessment of metric applies to at the level of a repository, not at the level of individual objects. For this reason, we excluded its assessment details from the F-UJI implementation. |
I1 | FsF-I1-01M Metadata is represented using a formal knowledge representation language. | The metadata of the object is available in a formal knowledge representation language, e.g., through at least one of the following mechanisms:
|
I1 | FsF-I1-02M Metadata uses semantic resources. |
|
I3 | FsF-I3-01M Metadata includes links between the data and its related entities. |
|
R1 | FsF-R1-01MD Metadata specifies the content of the data. |
|
R1.1 | FsF-R1.1-01M Metadata includes license information under which data can be reused. |
|
R1.2 | FsF-R1.2-01M Metadata includes provenance information about data creation or generation. |
|
R1.3 | FsF-R1.3-01M Metadata follows a standard recommended by the target research community of the data. |
|
R1.3 | FsF-R1.3-02D Data is available in a file format recommended by the target research community. |
|
Table 1. FAIRsFAIR object assessment metrics and summary of practical tests.
Practical tests design and rationale
Based on these metrics, our implementation of specific machine based FAIR assessment test is following standards, community best practises and scientific rationale which have been used to implement the assessment tool F-UJI:
Findability:
Unique and persistent object identification: Here we distinguish between uniqueness (FsF-F1-01D) and persistence (FsF-F1-02D) of a given identifier. The EOSC PID policy requires a PID to be globally unique, persistent, and resolvable which requires managed and governed infrastructures (Valle et al. 2020). Since no registry of accordingly valid persistent identifiers exists, we use the DataCite identifier type vocabulary (DataCite Metadata Working Group 2019) except identifiers exclusively used for print products and physical entities (e.g., ISBN, EAN, ROR). In addition, identifiers listed in identifiers.org are regarded to be persistent since these are managed and maintained.
Descriptive core metadata: Determining 'rich' metadata required to support data discovery (FsF-F2-01M), depends on the discipline and user requirements. However, ‘Findable’, refers to descriptive metadata as defined in the OAIS reference model (International Organization for Standardization 2012) ;ISO 14721:2012; (Lee 2009). Our practical tests are based on recommendations for data citation such as those proposed by Force11 (Data Citation Synthesis Group 2014) as well as the guidelines proposed by Earth Science Information Partners (ESIP) disciplinary best practices (ESIP Data Preservation and Stewardship Committee 2019). The International Association for Social Science Information Service and Technology (IASSIST) (Mooney and Newton 2012) as well as the cross-domain data citation recommendations provided by DataCite (Fenner et al. 2019). In addition to citation metadata, abstract or summary and keywords are vital to describe essential aspects of a data object. Additionally, we followed Fenner et al. (2019)’s advice to include the resource type within the metadata to distinguish research data objects from other digital objects.
The resulting set of core metadata properties (creator, title, publisher, publication date, summary, keywords, identifier) aligns well with existing recommendations for data discovery and core metadata definition such as EOSC Datasets Minimum Information (EDMI; (Asmi et al. 2017), the DataCite Metadata Schema (DataCite Metadata Working Group, 2019), the W3C Recommendation Data on the Web Best Practices (Lóscio, Burle, and Calegari 2017), and the Data Catalog Vocabulary (DCAT-2) specification (Albertoni et al. 2020). Further these metadata properties are supported by most domain agnostic metadata standards such as Dublin Core[7], DCAT-2, schema.org/Dataset[8], and DataCite schema.
Our practical tests verify the presence of metadata and in particular the presence of core data citation or core descriptive metadata defined above.
Searchable metadata: Searchability and discoverability of data objects (FsF-F4-01M) requires implementing common web standards supported by major search engines as well as research data portals. We focus on three mainstream metadata provision methods:
- providing ‘structured data’ metadata embedded in the landing page of a data set
- enabling content negotiation to deliver e.g. community specific metadata
- providing typed or Signposting links leading to additional metadata representations
Regarding structured data, the use of Schema.org JSON-LD encoded metadata and embedding Dublin Core meta elements in the landing page (Kunze 1999) are very often used. Both became very common to support search engine indexing during the last years (Huber et al. 2021). Other popular methods to embed metadata on the landing page are RDFa Core (Adida et al. 2015), the microdata syntax (Nevile and Brickley 2018), or the OpenGraph protocol[9].
The use of content negotiation to retrieve metadata is a W3C recommended approach to enable simple access to metadata for humans and machines and widely adopted by the research data community (see data on the Web recommendations by Loscio et al., 2016). This practice is currently gaining traction within the "open data" community through the emerging "content negotiation by profile" approach (Svensson, Atkinson, and Car 2019).
A currently emerging practice is providing links leading to external metadata descriptions within a landing page’s HTML head section following the typed links convention (RFC8228,(Nottingham 2010)) or following the Signposting recommendation[10] to include links in the HTTP response header (Van de Sompel and Nelson 2015).
All three practices above (structured data, content negotiation, and typed links) are verified in our implementation to test if an object's metadata is retrievable over the Web and to retrieve and parse the metadata required for the subsequent FAIR tests described in this document.
Verifying whether research data objects are ultimately included in common data catalogues is a challenge. Currently, we use the Google Dataset Search dataset as well as the interfaces provided by DataCite and Mendeley Data representing some of the leading interdisciplinary research data catalogues and search engines.
Inclusion of data identifiers: access to data objects (e.g. data files) is essential for and tested in FsF-F3-01M. The presence of data identifiers can be verified using domain agnostic standards (e.g. DataCite, schema.org/Dataset, and DCAT.) which provide specific metadata properties allowing us to specify data content in terms of e.g. download links. Further recognition of identifiers encoded in domain specific metadata standards such as EML, DDI or ISO19139 can be implemented. In addition, presence of data identifiers which have been made available through other mechanisms such as the above-mentioned typed links or Signposting type links can be verified.
Accessibility:
Access level specification: humans as well as machines need to understand given access rights and restrictions or rights in order to either retrieve the data accordingly or avoid unnecessary access attempts. The indication of access levels is also important due to the ‘as open as possible’ FAIR community consensus (e.g.(Mons et al. 2017) or (Boeckhout, Zielhuis, and Bredenoord 2018). Therefore a practical test of the metric FsF-A1-01M can verify the presence of data access levels (e.g., public, embargoed, restricted) within appropriate metadata fields. It can also be verified that/if access levels are expressed using formal vocabularies and associated identifiers of e.g. the COAR controlled vocabulary for access rights[11], the Eprints AccessRights vocabulary encoding scheme[12], the EU publications access rights terms[13], or the OpenAire access rights[14] definition.
Data and metadata access protocols: metadata and data need to be accessible through a standard communication protocol (FsF-A1-02M and FsF-A1-03D). A variety of protocol standards have been defined during the last decades. However, some of them are deprecated (e.g., Apple Filing Protocol, Gopher, see e.g. (Lee 1999)), leaving only a comparatively small number of machines and human-friendly web protocols in use which include (s)http(s), (s)ftp, ssn, svn, telnet, rtsp and ws(s). A possible practical test we implemented is therefore to extract the URI scheme (RFC7595; (Thaler, Hansen, and Hardie 2015)) of a given URI and verify if the scheme corresponds to those shared application-layer protocols.
Deleted research data objects: The verification of persistence of metadata even when a data set has been deleted (FsF-A2-01M), sometimes referred to as ‘tombstoning’, is an important FAIR metric that is virtually impossible to test however during the implementation of tests we found that it is hardly possible to test this at data set level. Handling of deleted data and metadata records strongly depends on policies and procedures at the repository level. For example if these repositories maintain so-called tombstone pages in case a data set has been deleted. However, no machine-interpretable indicator of tombstone status exists to date. We therefore decided to not include this metric for the current assessment implementation.
Interoperability
Knowledge representation language: Metric FsF-I1-01M is dealing with the presence of semantic technologies. Making the metadata document available in a knowledge representation language requires the use of appropriate serialisation formats such as RDF, RDFS, OWL. F-UJI verifies the presence of a knowledge representation language by checking if the collected metadata is serialized as JSON-LD or RDFa (Landing Page Content) or e.g. provided via Content Negotiation in one of the serialization formats for RDF (e.g. Turtle, XML, JSON-LD) recognized by the Python library RDFlib[15].
Semantic resources: Regarding semantic resources (FsF-I1-02M) we assume that the namespaces of semantic resources available in a metadata document indicate that corresponding terms are also used. We do not consider generic namespaces (e.g., of RDF, RDFS, XSD) but focus on namespaces representing semantic resources such as ontologies, thesauri, and taxonomies. BecauseUnfortunately no complete, authoritative, cross-domain semantic resources registry exists, therefore we collated metadata from two sources, Linked Open Vocabularies (LOV)[16] and Linked Open Data Cloud[17]. Deprecated semantic resources are excluded during the process. We regard this as an interim solution to verify the presence or absence of used semantic resources which probably will be substituted or emended by future projects and initiatives and emerging services such as Fairsharing[18].
Related resources: links to related entities (FsF-I3-01M) such as prior version, associated datasets, publications help to understand the broader context of research data objects. Commonly used relation types are listed in the DataCite Metadata Schema (DataCite Metadata Working Group, 2019) or the Dublin Core terminology. The practical tests make use of relations indicated by PROV-O terms (Moreau et al. 2011) or generic related resources indicated in metadata e.g. in Dublin Core records. In general, machine-readable unique or persistent identifiers are best suited to denote related entities, but the test also accepts the presence of free text expressions of, for example, references.
Reusability
Data content descriptors: To ease processing of data, metadata should include technical properties (file format and size) or content descriptors (measured variables) of a data object. The implementation of FsF-R1-01MD therefore verifies the presence of data content descriptors in appropriate fields of metadata records. It further checks if a resource type is given and validates the values of the descriptors against the actual data file. Apache Tika is here used for content analysis. The content descriptors we defined are based on the recommendations (Austin et al. 2019) of the RDA Data Fitness for Use Working Group[19].
Data licence: Users need to know under which conditions the data may be reused, so the metadata should contain an explicit licence statement. Our implementation of metric FsF-R1.1-01M therefore checks if a data object's licence is specified using an appropriate metadata field. This test checks if a valid licence identifier (URL) is used but also tries to recognize free text licence strings. For reference, we use the SPDX licence list[20] to verify that a standard licence is used.
Provenance: Provenance related metadata (FsF-R1.2-01M) depends on data type purpose and application (Herschel, Diestelkämper, and Ben Lahmar 2017) which makes it difficult to define a cross-domain set of provenance properties. Therefore, we focus on provenance information related to data creation following the PROV W3C definition (Groth and Moreau 2013) which is suitable for data on the web in general (Hartig 2009). To distinguish data creation provenance metadata in domain agnostic metadata standards we use existing mappings to the PROV-O ontology (e.g. (Garijo and Eckert 2013)) to capture properties for data sources, data creation or collection date, actors involved in data creation, modification, and versioning information. In addition, we check if data provenance information is accessible in a machine-readable way using specialised vocabularies and ontologies such as PROV-O (Moreau et al. 2011) or PAV (Ciccarese et al. 2013).
Community standards: Developing automated tests to verify the presence of community specific metadata (FsF-R1.3-01M) is a challenge since data providers may offer a data object's metadata by methods which are not necessarily linked or connected to a PID or landing page URI. For example, common harvesting protocol endpoints for e.g. OAI-PMH and Catalog Service for the Web (CSW) currently can not be included in most metadata standards. Furthermore, some of these services, especially OAI-PMH, cannot use the same identifier (PID) that was used to publish the object (Huber et al, 2021). An interim solution is to retrieve a data repository ID from DataCite REST API which offers provider identifiers[21] collected as part of its PID registration service in re3data. We use these provider IDs to retrieve information about metadata access endpoints from registries such as FAIRsharing and re3data.org, and the supported metadata standards listed there. Since this approach is limited to objects registered with PIDs via Datacite, F-UJI accepts service endpoints URI as additional input parameters, verifies that associated domains match each other and uses these interfaces to retrieve domain specific standards. Initially the tool supports OAI-PMH, CSW and SPARQL and compares the namespaces included in all retrieved metadata documents with the namespaces of domain metadata standards listed in the RDA Metadata Standards Catalog[22] which we use as an initial reference to identify the ‘target community-standard namespace’ tuple required for the test.
Community file formats: Some aspects have to be considered when choosing community-appropriate file formats to implement FsF-R1.3-02D: their long-term usability and standardisation as well as discipline specific analytical requirements. In general, long term file formats and open, standard file formats can be regarded as beneficial for the scientific community. The scientific community also needs discipline-specific and multidisciplinary scientific file formats that simplify data analysis workflows. Several databases exist which provide access to a large number of file formats and associated mime types[23] but these registries do not indicate potential scientific target user communities. Unfortunately no authoritative registry for scientific file formats yet exists. As an interim solution we curate an extensible controlled list of scientific formats which is available at Github[24], which includes associated mime types and scientific target communities. The list was compiled from the Archive Team list of scientific file formats[25] and the Wolfram Alpha list of supported scientific file formats[26]. Our list also includes some generic file formats taken from the Library of Congress Recommended Formats list[27]. Similarly, we assembled two extensible, controlled lists dedicated to long term and open formats based on the ISO/TR 22299[28] digital file format recommendations for long-term storage, the Wikipedia list of open formats[29] as well as the openformats.org[30] initiative format list. We verify file formats and associated mime types detected within the metadata of a given data set and test if these are recorded in the lists mentioned above to distinguish scientifically recommended file formats such as long term file format, open file format or scientific file format.
References
Adida, B., M. Birbeck, S. McCarron, and I. Herman. 2015. “RDFa Core 1.1 - Third Edition.” W3C Recommendation. The World Wide Web Consortium (W3C). https://www.w3.org/TR/rdfa-core/.
Albertoni, R., S. Cox, A. Gonzalez Beltran, A. Perego, and P. Winstanley. 2020. “Data Catalog Vocabulary (DCAT) - Version 2.” W3C Recommendation. The World Wide Web Consortium (W3C). https://www.w3.org/TR/vocab-dcat-2/.
Ammar, Ammar, Serena Bonaretti, Laurent Winckers, Joris Quik, Martine Bakker, Dieter Maier, Iseult Lynch, Jeaphianne van Rijn, and Egon Willighagen. 2020. “A Semi-Automated Workflow for FAIR Maturity Indicators in the Life Sciences.” Nanomaterials (Basel, Switzerland) 10 (10). https://doi.org/10.3390/nano10102068.
Asmi, A., B. Cordewener, C. Goble, D. Castelli, E. Kühn, F. Pasian, F. Niccolucci, et al. 2017. “D6.6: 2nd Report on Data Interoperability.” EOSCpilot. https://ec.europa.eu/research/participants/documents/downloadPublic?documentIds=080166e5bbdb1165&appId=PPGMS.
Austin, C., H. Cousijn, M. Diepenbroek, J. Petters, and M. Soares E Silva. 2019. “WDS/RDA Assessment of Data Fitness for Use WG Outputs and Recommendations.” RDA. https://doi.org/10.15497/RDA00034.
Bahim, C., M. Dekkers, and B. Wyns. 2019. “Results of an Analysis of Existing FAIR Assessment Tools.” Research Data Alliance. May 23, 2019. https://doi.org/10.15497/RDA00035.
Baker, Monya. 2016. “Digital Badges Motivate Scientists to Share Data.” Nature, May. https://doi.org/10.1038/nature.2016.19907.
Berners-Lee, T. 2006. “Linked Data.” 2006. https://www.w3.org/DesignIssues/LinkedData.html.
Boeckhout, Martin, Gerhard A. Zielhuis, and Annelien L. Bredenoord. 2018. “The FAIR Guiding Principles for Data Stewardship: Fair Enough?” European Journal of Human Genetics: EJHG 26 (7): 931–36.
Ciccarese, Paolo, Stian Soiland-Reyes, Khalid Belhajjame, Alasdair Jg Gray, Carole Goble, and Tim Clark. 2013. “PAV Ontology: Provenance, Authoring and Versioning.” Journal of Biomedical Semantics 4 (1): 37.
Collins, S., F. Genova, N. Harrower, S. Hodson, S. Jones, L. Laaksonen, D. Mietchen, R. Petrauskaite, V. Magnus, and P. Wittenburg. 2018. “Turning FAIR into Reality. Final Report and Action Plan from the European Commission Expert Group on FAIR Data.” Publications Office of the European Union. doi: 10.2777/1524.
Cox, S., and J. Oznome Yu. 2018. “5-Star Tool: A Rating System for Making Data FAIR and Trustable.” In Proceedings of the 2018 eResearch Australasia Conference, Oct, 16–20.
Data Citation Synthesis Group. 2014. “Joint Declaration of Data Citation Principles.” Edited by Mercè Crosas. FORCE11. https://doi.org/10.25490/a97f-egyk.
DataCite Metadata Working Group. 2019. “DataCite Metadata Schema Documentation for the Publication and Citation of Research Data. Version 4.3.” DataCite e.V. 2019. https://doi.org/10.14454/7xq3-zf69.
Devaraju, Anusuriya, and Patricia Herterich. 2020. “D4.1 Draft Recommendations on Requirements for Fair Datasets in Certified Repositories,” February. https://doi.org/10.5281/zenodo.3678716.
Devaraju, Anusuriya, Mustapha Mokrane, Linas Cepinskas, Robert Huber, Patricia Herterich, Jerry de Vries, Vesa Akerman, Hervé L’Hours, Joy Davidson, and Michael Diepenbroek. 2021. “From Conceptualization to Implementation: FAIR Assessment of Research Data Objects.” Data Science Journal 20 (1). https://doi.org/10.5334/dsj-2021-004.
Doorn, P., and I. Dillo. 2017. “Assessing the FAIRness of Datasets in Trustworthy Digital Repositories: A 5 Star Scale.” https://indico.cern.ch/event/588219/contributions/2384979/attachments/1426152/2188462/Dillo_Doorn_-_Assessing_FAIRness_CERN_Geneva_13-03-2017-3.pdf.
ESIP Data Preservation and Stewardship Committee. 2019. “Data Citation Guidelines for Earth Science Data, Version 2.” ESIP. https://doi.org/10.6084/m9.figshare.8441816.v1 .
FAIR Data Maturity Model Working Group. 2020. FAIR Data Maturity Model. Specification and Guidelines. https://zenodo.org/record/3909563.
Fenner, Martin, Mercè Crosas, Jeffrey S. Grethe, David Kennedy, Henning Hermjakob, Phillippe Rocca-Serra, Gustavo Durand, et al. 2019. “A Data Citation Roadmap for Scholarly Data Repositories.” Scientific Data 6 (1): 28.
Gaiarin Pittonet, S. 2020. FAIR Assessement and Certification in the EOSC Region. https://doi.org/10.5281/zenodo.4486280.
Garijo, D., and K. Eckert. 2013. “Dublin Core to PROV Mapping.” W3C Working Group Note. The World Wide Web Consortium (W3C). https://www.w3.org/TR/prov-dc/.
Groth, P., and L. Moreau. 2013. “PROV-Overview - An Overview of the PROV Family of Documents.” W3C Working Group Note. The World Wide Web Consortium (W3C). https://www.w3.org/TR/prov-overview/.
Hartig, O. 2009. “Provenance Information in the Web of Data.” In Proceedings of the Linked Data on the Web Workshop (LDOW) at WWW (2009). CEUR Workshop Proceedings. http://ceur-ws.org/Vol-538/ldow2009_paper18.pdf.
Herschel, Melanie, Ralf Diestelkämper, and Houssem Ben Lahmar. 2017. “A Survey on Provenance: What for? What Form? What From?” The VLDB Journal: Very Large Data Bases: A Publication of the VLDB Endowment 26 (6): 881–906.
Huber, Robert, Claudio D’Onofrio, Anusuriya Devaraju, Jens Klump, Henry W. Loescher, Stephan Kindermann, Siddeswara Guru, et al. 2021. “Integrating Data and Analysis Technologies within Leading Environmental Research Infrastructures: Challenges and Approaches.” Ecological Informatics 61 (March): 101245.
International Organization for Standardization. 2012. “Space Data and Information Transfer Systems - Open Archival Information System (OAIS) - Reference Model.” ISO 14721:2012. ISO.
Kidwell, Mallory C., Ljiljana B. Lazarević, Erica Baranski, Tom E. Hardwicke, Sarah Piechowski, Lina-Sophia Falkenberg, Curtis Kennett, et al. 2016. “Badges to Acknowledge Open Practices: A Simple, Low-Cost, Effective Method for Increasing Transparency.” PLoS Biology 14 (5): e1002456.
Kunze, John. 1999. “Encoding Dublin Core Metadata in HTML.” Dublic Core Metadata Initiative Memo. Internet Engineering Task Force (IETF). https://www.ietf.org/rfc/rfc2731.txt.
Lee, C. 1999. “Where Have All the Gophers Gone? Why the Web Beat Gopher in the Battle for Protocol Mind Share.” 1999. https://ils.unc.edu/callee/gopherpaper.htm.
Lee, C. A. 2009. “Open Archival Information System (OAIS) Reference Model.” In Encyclopedia of Library and Information Sciences, Third Edition, 4020–30. CRC Press.
L’Hours, Hervé, Angus Whyte, Marjan Grootveld, Ilona von Stein, and de Vries Jerry. 2021. Capability Maturity & Community Engagement Design Statement. https://doi.org/10.5281/zenodo.4705235.
Lóscio, B. F., C. Burle, and N. Calegari. 2017. “Data on the Web Best Practices.” W3C Recommendation. The World Wide Web Consortium (W3C). https://www.w3.org/TR/dwbp.
Martinez-Ortiz, Carlos, Mateusz Kuzak, Jurriaan H. Spaaks, Jason Maassen, and Tom Bakker. 2020. Five Recommendations for “FAIR Software.” https://doi.org/10.5281/zenodo.4310217.
Mons, Barend, Cameron Neylon, Jan Velterop, Michel Dumontier, Luiz Olavo Bonino da Silva Santos, and Mark D. Wilkinson. 2017. “Cloudy, Increasingly FAIR; Revisiting the FAIR Data Guiding Principles for the European Open Science Cloud.” Information Services & Use 37 (1): 49–56.
Mooney, Hailey, and Mark P. Newton. 2012. “The Anatomy of a Data Citation: Discovery, Reuse, and Credit.” Journal of Librarianship and Scholarly Communication 1 (1): 1035.
Moreau, Luc, Ben Clifford, Juliana Freire, Joe Futrelle, Yolanda Gil, Paul Groth, Natalia Kwasnikowska, et al. 2011. “The Open Provenance Model Core Specification (v1.1).” Future Generations Computer Systems: FGCS 27 (6): 743–56.
Mosconi, Gaia, Qinyu Li, Dave Randall, Helena Karasti, Peter Tolmie, Jana Barutzky, Matthias Korn, and Volkmar Pipek. 2019. “Three Gaps in Opening Science.” Computer Supported Cooperative Work: CSCW: An International Journal 28 (3): 749–89.
Nevile, C., and D. Brickley. 2018. “HTML Microdata.” W3C Working Draft. The World Wide Web Consortium (W3C). https://www.w3.org/TR/microdata/.
Nottingham, M. 2010. “Web Linking.” Internet Engineering Task Force (IETF). https://tools.ietf.org/html/rfc5988.
Svensson, L. G., R. Atkinson, and N. J. Car. 2019. “Content Negotiation by Profile.” W3C Working Draft. The World Wide Web Consortium (W3C). https://www.w3.org/TR/dx-prof-conneg/.
Thaler, D., T. Hansen, and T. Hardie. 2015. “Guidelines and Registration Procedures for URI Schemes.” Best Current Practice. Internet Engineering Task Force (IETF). https://datatracker.ietf.org/doc/html/rfc7595.
Valle, Mrio, André Heughebaert, Rachael Kotarski, Tobias Weigel, Raphael Ritz, Brian Matthews, Paolo Manghi, Anders Sparre Conrad, Maggie Hellström, and Peter Wittenburg. 2020. A Persistent Identifier (PID) Policy for the European Open Science Cloud (EOSC). Publications Office of the European Union.
Van de Sompel, Herbert, and Michael L. Nelson. 2015. “Reminiscing about 15 Years of Interoperability Efforts.” D-Lib Magazine: The Magazine of the Digital Library Forum 21 (11/12). https://doi.org/10.1045/november2015-vandesompel.
Wilkinson, Mark D., Michel Dumontier, I. Jsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg, et al. 2016. “The FAIR Guiding Principles for Scientific Data Management and Stewardship.” Scientific Data 3 (March): 160018.
[1] https://doi.org/10.5281/zenodo.4118405
[2] https://fairsfair.eu/fair-aware
[3] https://fairsfair.eu/f-uji-automated-fair-data-assessment-tool
[4] https://www.surveymonkey.com/r/fairdat
[6] https://www.rd-alliance.org/groups/metadata-standards-catalog-working-group.html
[5] https://docs.google.com/forms/d/e/1FAIpQLSf7t1Z9IOBoj5GgWqik8KnhtH3B819Ch6lD5KuAz7yn0I0Opw/viewform
[7] https://dublincore.org/specifications/dublin-core/
[8] https://schema.org/Dataset
[11] http://vocabularies.coar-repositories.org/documentation/access_rights/
[12] http://www.ukoln.ac.uk/repositories/digirep/index/Eprints_AccessRights_Vocabulary_Encoding_Scheme
[13] http://publications.europa.eu/resource/authority/access-right
[14] https://guidelines.openaire.eu/en/latest/data/field_rights.html
[15] https://github.com/RDFLib
[16] https://lov.linkeddata.es/dataset/lov/
[18] https://fairsharing.org
[17] https://lod-cloud.net/
[19] https://www.rd-alliance.org/groups/assessment-data-fitness-use
[20] https://spdx.org/licenses/
[23] https://www.nationalarchives.gov.uk/PRONOM/
[24] https://github.com/pangaea-data-publisher/fuji/blob/master/fuji_server/data/science_formats.json
[25] http://justsolve.archiveteam.org/wiki/Scientific_Data_formats
[27] https://www.loc.gov/preservation/resources/rfs/TOC.html
[28] https://www.iso.org/standard/73117.html
[29] https://en.wikipedia.org/wiki/List_of_open_formats
[30] https://web.archive.org/web/20060215074955/http://www.openformats.org/enShowAll